Adapting AI to the Plant Floor
Smart technologies enable engineers to predict failures, detect suboptimal operations and identify quality problems.

Fig. 1: AI and machine learning help enable manufacturing engineers to combine data across industrial data sources to identify problems and automate actions to improve production. Image courtesy of Siemens Digital Industries.


Latest News
June 15, 2020
Manufacturers are now deploying artificial intelligence (AI) on the plant floor, with tools such as machine learning (ML) models proving to be incredibly valuable in manufacturing processes. These smart technologies help engineers predict failures, detect suboptimal operations and identify quality problems (Fig. 1). But there’s a catch: Conventional AI and ML practices don’t always work well within the prevailing operating parameters of the manufacturing arena.
Today, plants that implement AI and ML must overcome significant challenges that arise when creating the data sets used to train manufacturing process models. To do this, companies need tools and techniques that will help them adapt AI technologies to the dynamics, complexity and multi-dimensionality of the manufacturing environment (Fig. 2).
Getting Training Data
In a recent MAPI Foundation survey titled “The Manufacturing Evolution: How AI Will Transform Manufacturing & the Workforce of the Future,” 58% of the respondents reported that the most significant barrier to deployment of AI solutions revolved around a lack of data resources.
This problem stems from the trends shaping today’s manufacturing environment. For example, broad adoption of flexible manufacturing practices has opened the door for an increased product customization, which has resulted in smaller production runs and reduced the amount of data available for AI models, making the training process less than cost effective, if not impractical.
In addition, Six Sigma methodologies implemented by original equipment manufacturers (OEMs) and Tier One suppliers have reduced the number of defects encountered during production runs, sometimes to as few as three to four defects per million parts. The rarity of these defects makes it difficult for manufacturers to collect sufficient data to train visual inspection models.
Furthermore, the emergence of the Industrial Internet of Things (IIoT) has brought much more dynamic and complex conditions on the plant floor, which further complicates the training data collection and increases the variables that come into play in the manufacture of products. This has proven to be particularly true of mission- and safety-critical systems.
“The more complex and multi-dimensional the mission-critical system is, the more high-quality data is needed to develop an accurate AI system,” says Viji Krishnamurthy, senior director of product management, Oracle IoT and blockchain apps. “If we define the complexity and dimensionality of the mission-critical system via the sources of data and types and dimensions of data, as well as the interdependency of the data and events, we need data that represents all variants of real-world events of this mission-critical system for developing effective AI.”
As a result of these factors, AI implementers in manufacturing either don’t have enough data to train AI models using traditional techniques or find the creation of large data sets too costly and time-consuming. These conditions contrast starkly with internet-enabled consumer applications, where product developers can cost-effectively tap data from billions of users to train powerful AI models.
“When engineers try to use supervised learning in a manufacturing application, they run a lot of iterations to see how fast the model is learning,” says Patrick Sobalvarro, CEO of Veo Robotics. “When they say they have a training problem, what they’re typically saying is that the model just doesn’t learn very fast, and it’s not economical to keep training it, especially given that mass customization means shorter runs and higher part variability. As a result, you can’t amortize the cost of generating a large training set over the life of its utility. The engineering cost in delay and dollars is too high.”
Labeling Can Be a Challenge
The scarcity of data, however, is not the only factor impeding AI and ML implementation in manufacturing. Today, the foundation for any such project is a well-curated training data set, and this requires thorough data labeling. Labeling, however, poses barriers on multiple levels.
For one, labeling and categorizing training data make significant demands on engineering teams.
“Labeling requires deep domain experts due to the specialized knowledge required for labeling in manufacturing applications,” says Achalesh Pandey, technology director for artificial intelligence at GE Research. “For example, parts inspection data labeling requires certified inspectors.”
“The more complex and multi-dimensional the mission-critical system is, the more high-quality data is needed to develop an accurate AI system.”
The process is further complicated by the complexity of the manufacturing environment, which can make labeling prohibitively time-consuming. For example, if mission-critical system models are based on multiple sources of input—which is typically the case in manufacturing—the system suffers from dimensionality, requiring large sets of labeled data. When knowledge of the data sources is scarce, manual labeling becomes daunting because of the dimensionality, large data sets and frequency of new data collection.
Despite these challenges, “current applications and trends show that data labeling will be part of AI developments in the future,” says Alejandro Betancourt, senior machine learning tech lead at Landing AI. “This reinforces the importance of defining data acquisition and labeling strategies directly connected to model training and deployment capabilities.”
To help, new model-training techniques have emerged that promise to mitigate the challenges posed and provide the means to generate synthetic data. These methodologies aim to help manufacturers build the data repositories needed to train and even pre-train ML models.
Developers contend that these techniques will expand the reach of AI and ML in the manufacturing sector, enabling engineers to boost model performance and achieve better accuracy and reliability without large training data sets.
Spoofing Data
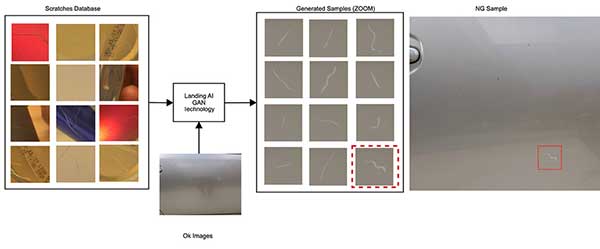
The most prominent of these techniques takes the form of algorithmic architectures called generative adversarial networks (GANs). Here, the engineer uses two neural networks, and pits one against the other to generate synthetic data that passes for real data.
Using this technique, a generator network chooses either a real data point or a fabricated data point and passes it to the discriminator network. The goal of the second network is to guess whether the data point is real or synthetic. If the discriminator network correctly differentiates between the two, the generator network uses the insights that it has gained in the process to fine-tune its next attempt, learning from each correct decision.
As this process progresses, the generator network becomes adept at creating synthetic data so that the discriminator network cannot distinguish between real and synthetic data. The engineer then uses the synthetic data to train the ML model.
This methodology has proven to be particularly helpful in manufacturing applications involving videos and images. GANs allow engineers to generate millions of scenarios and determine if their algorithms are reliable enough to operate safely.
“By using GANs, a manufacturer may be able to take 10 images of a rare defect and synthesize an additional 1,000 images that an AI can then learn from,” says Betancourt. “Recent advances in GAN technology are already proving its benefits, reducing by more than 10 times the data required to achieve a particular performance level to detect scratches in metallic components.”
Learning by Example
Transfer learning is another technique that has proven to be effective in applications where training data is scarce or unavailable. Using this design methodology, the engineer takes the knowledge extracted by an ML model that has already been trained and applies it to a different but related problem, leveraging previously acquired data without starting from scratch.
Basically, transfer learning represents a way to exploit what has been learned in one task to improve generalization in another.
Conventional wisdom does not yet offer any hard-and-fast rules on when to use this technique, but an engineer dealing with a situation where there isn’t enough labeled training data can lean on a few rules.
For example, transfer learning works well when there already exists a network pre-trained on a similar task, especially if it has been trained on large amounts of data. Also, transfer learning usually works well when the trained task and the untrained task use the same input.
“Transfer learning enables AI to learn from a related task where there is ample data available and then uses this knowledge to help solve the small data task,” says Betancourt. “For example, AI learns to find dents from 1,000 pictures of dents collected from a variety of products and data sources. It can then transfer this knowledge to detect dents in a specific product with only a few samples (Fig. 3).”
As with other AI technologies, transfer learning has its fair share of challenges. One of the biggest limitations confronting users is the problem of negative transfer. In these situations, transfer learning works only if the initial and target problems are similar enough for the first round of training to be relevant.
Fine-Tune Manufacturing Processes
A technique that aims to alleviate some of the pressure from data scarcity and labeling, reinforcement learning allows algorithms to learn tasks simply by trial and error, via a sequence of decisions. Every time an algorithm attempts to perform a task, it receives a reward—such as a higher score—if the action is successful or a “punishment” if it isn’t.
Reinforcement learning differs from the supervised learning in that the process does not require large amounts of labeled input/output pairs to act as a training set, nor does it need to know the desired answer ahead of time.
Most learning in this instance happens as the software interacts with its environment over several iterations, eventually formulating the correct policy and describing the actions to be taken. The software can even learn to achieve a goal in an uncertain, potentially complex environment.
“Developing models for process optimization can lend itself to using reinforcement learning models, especially if the process has a reasonably accurate simulator of the process,” says Randy Groves, vice president of engineering at SparkCognition.
“Reinforcement learning excels at cases where the current state is well-described and the desired results are crisply defined,” Groves adds. “This is known as the reward function. For example, a simulator of a beverage bottling plant could be used to train a reinforcement learning model to learn how to make the most soft drink bottles with the least amount of water and power consumption.”
Low-Shot Learning Gets Big Picture
As with the previously discussed techniques, one-shot and few-shot learning aim to teach algorithms from small amounts of training data. These techniques operate on the premise that engineers can create reliable algorithms to make predictions from minimalist data sets.
Using these low-shot learning techniques, the engineer uses a single or a few examples to establish categorization constraints, which are then used to classify similar objects in future applications.
For example, a model may be given thousands of easy inspection tasks, where each task has only a small number of samples. This forces the model to learn on and identify only the most important patterns. The engineer then takes what has been learned from these tasks and applies it to the application at hand. Thus, the performance of the new model benefits from what has been learned from similar, smaller tasks.
In addition to being used in applications suffering from a shortage of training data, low-shot techniques also target situations where the engineer is working with a huge data set, and correctly labeling the data is too costly.
Manufacturers typically use low-shot learning techniques to create object-categorization models that support industrial use cases such as defect detection.
The Need for Explainability
The examination of training methods for ML models drives home the point that AI and automation engineers must understand and be able to interpret the factors that lead models to their decisions and predictions.
“It’s important for engineers to understand how and why an algorithm reached its recommendations, and why certain factors and not others were critical,” says Matthew Wells, vice president of digital product management at GE Digital. “By digging into the insight, engineers can better understand their processes for making improvements.”
Considered within the context of manufacturing operations, detailed explanations and traceability become particularly important when the ML pipeline connects to mission- and safety-critical applications. At these points, significant risks to companies and their employees come into play, and the future dynamic between humans and machines are determined.
Take, for example, instances where machines and humans work closely together. “In manufacturing applications, the collaboration between human operators and the AI-based decision process is crucial,” says Matthias Loskyll, director of advanced artificial intelligence, factory automation, at Siemens Digital Industries. “It is to be expected that humans will not disappear with increasing automation, but that their role will change significantly. One of these roles is to oversee the AI-based system. Because the average operator will not have a deep knowledge of AI or ML, the AI needs to be able to explain the decisions.”
Explainability also lays the vital groundwork for broader acceptance of AI technologies in manufacturing by building trust in AI systems.
“End users require explainable AI model output to be comfortable in adopting the technology,” says Pandey.
More GE Digital Coverage
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News


