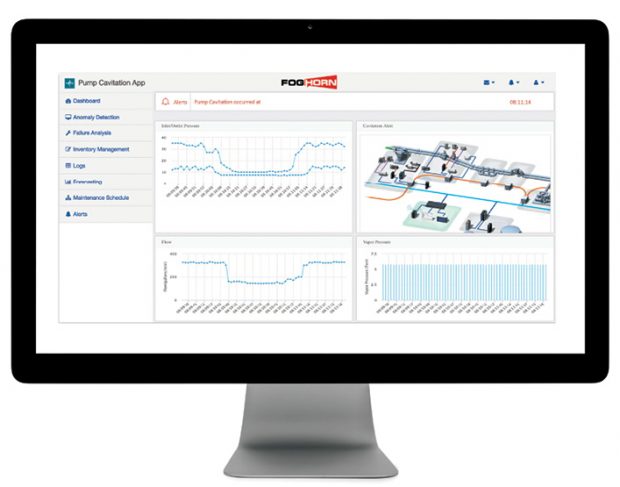
The FogHorn Lighting platform supports real-time analytics applications running on ultra-small footprint edge devices. The software allows application developers, systems integrators and production engineers to build high-performance edge analytics systems for industrial IoT (IIoT) applications. Image courtesy of FogHorn Systems.


Latest News
January 2, 2018
As the internet of things (IoT) took shape, many network architects and device designers assumed that the primary function of “things” was to collect and transmit data, occasionally performing simple analytics. They saw clusters of powerful servers in the cloud performing most of the analysis on the resulting flood of data. Now that tide seems to be turning.
Increasingly, technologists and developers have come to realize that for the IoT to grow and deliver value, designers must set aside this approach and adopt a paradigm that gives machines with greater analytical capabilities a larger role in the age of big data. These systems will integrate algorithms, business rules, machine learning code and predictive analytics, along with hardware such as processors, sensors and communications modules. As a result, the machines will raise the bar on the intelligence that they provide, combining sensor data with human input to deliver real-time, contextualized information.
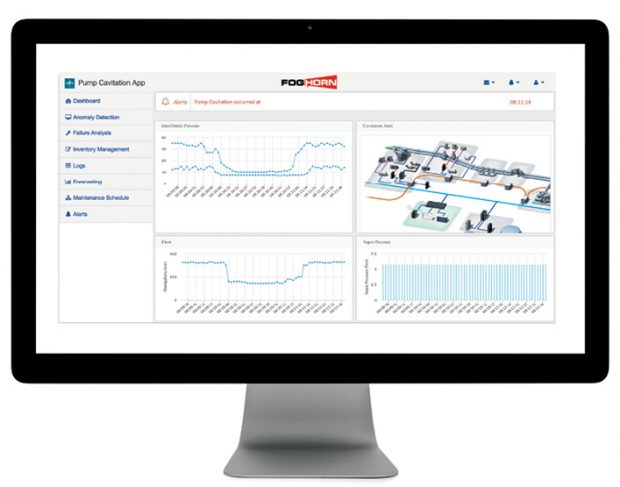 The FogHorn Lighting platform supports real-time analytics applications running on ultra-small footprint edge devices. The software allows application developers, systems integrators and production engineers to build high-performance edge analytics systems for industrial IoT (IIoT) applications. Image courtesy of FogHorn Systems.
The FogHorn Lighting platform supports real-time analytics applications running on ultra-small footprint edge devices. The software allows application developers, systems integrators and production engineers to build high-performance edge analytics systems for industrial IoT (IIoT) applications. Image courtesy of FogHorn Systems.With these new machines, designers can implement “edge analytics,” a computing paradigm in which data is stored, processed and analyzed closer to where the data is generated—as opposed to all the data being sent to the cloud for processing and extracting insights. This means rethinking how, when and where data is best analyzed—and more specifically, what functionality will be embedded in the majority of the devices at the network’s edge.
“Edge analytics brings data science to the ‘edge,’ right next to the machine or sensors generating raw data streams,” says Ramya Ravichandar, director of product management at FogHorn Systems. “Traditional methods of analytics and big data computing rely on batch data analysis that requires sending all data to the cloud. Edge computing analyzes and processes data as soon as it is produced, with very low latency.”
This results in edge devices that deliver real-time insights, enabling immediate business-impacting decisions.
Differing Views on Data
Just how much data analysis and decision-making should occur on these new machines at the network’s edge? Early IoT architects parsed analytics in three tiers, with simple analysis performed on stand-alone smart devices, more complex multi-device analysis runs on gateways, and “heavy lifting” performed in the cloud. But this has changed.
Recent technological advances have freed designers from many of the constraints of the tier system. For example, advances in system-on-a-chip technology have enabled some commercial devices to be powerful enough to run full-fledged operating systems and complex algorithms, and include significant memory. These devices also incorporate a rich variety of sensors and connectivity options. The growing abundance of computing and memory resources now allows increasingly complex functions to be performed at the edge of the network.
Economies of technology are also changing IoT analytics architectures. “Factors like the cost of the bandwidth to move the data to and from the cloud, the latency associated with moving the data, a low tolerance for interrupted or intermittent connection and the need to keep data private and secured are influencing modern architectures,” says David Formisano, director of internet of things strategy at Intel. “Finally, the emergence of artificial intelligence at the edge—utilization of advances in machine learning and deep learning—is creating brand-new use cases and applications that were not possible only a few years ago.”
Most technology observers agree that these changes have altered the cloud’s role in IoT data analysis, contending that devices and gateways can now perform more and more of the hardcore analysis. But developers of IoT platforms do not agree on the precise role of the various levels of the network.
Some put the emphasis on gateways. “We find that most IIoT [industrial internet of things] deployments are processing data at a gateway level as opposed to a single smart device,” says Ravichandar. “The challenge with relying on the cloud to do the majority of data processing is the bandwidth cost to move that data—especially when it’s streaming in real time—and the latency for processing and transferring insights back to the factory floor.
Others see the device as a key player. “One component to the data that is acquired from IIoT sensors is a real-time requirement, where one may have to quickly act to prevent a machine failure or a process contamination,” says Tom Kovanic, technical marketing manager for Panduit. “This aspect of the data is best processed on the edge, as near to the sensors as possible because this shortens latency and therefore improves the response time.”
Still others see the device as a venue for pre-processing, having edge analytics filter data where it is created. In these cases, data that falls within normal parameters or is irrelevant to the application is ignored and retained in low-cost storage. On the other hand, abnormal readings or more relevant data is sent to the cloud for more intensive analysis.
Early advocates of edge analytics contend that intensive analysis does not always have to occur in the cloud. “While we agree with the notion of distributed intelligence, we don’t agree that heavy lifting analytics functions will always be performed in the cloud,” says Formisano.
Adopting the new machine paradigm and embracing edge analytics does not, however, take the cloud out of the picture. In fact, changing technology, such as machine learning, has created new roles for the cloud. For example, “a long-term component of IoT data is its use to develop the predictive analytics models, based on fleets of sensors and factoring in other contextual system data,” says Kovanic. “Since this data does not need to be processed in real time, it is best processed in the cloud, where one has ample compute and storage resources.”
How the Pieces Fit Together
To get a clearer picture of where edge and cloud analytics fit into the bigger picture, design engineers have to drill down and look at specific applications. In doing so, they can extract rules of thumb that will guide them through the development process.
“We see that there are both edge-centric and cloud-centric analytics approaches in every vertical market segment,” says Formisano. “So it is best to look at the use case vs. the vertical application.”
In this examination, engineers should look at the use cases within the context of the four main drivers of edge analytics:
- the cost of the bandwidth to move data to and from the cloud;
- the latency associated with moving the data;
- a low tolerance for interrupted or intermittent connections; and
- the need to keep data private and secure.
An example of where the cost of the bandwidth comes into play can be seen in surveillance, retail and industrial monitoring applications. In these cases, context-aware video anomaly detection plays a key role. Edge analytics matches up well with these applications because it avoids the cost of sending raw video, especially high-definition or 4K, to the cloud for all the processing, which would be prohibitive.
To see latency’s role in the dynamics, consider industrial robotics applications. In this use case, humans and robots interact on the production floor. This requires safety mechanisms that can stop robots from injuring human workers. Here, edge analytics serve well because they can ensure near real-time response and control, sidestepping occasions where latency or intermittent connectivity to the cloud can compromise services and jeopardize safety.
Similarly, edge analytics represents the best option for condition-based monitoring of assets in remote areas, such as oil and gas production facilities and shipping, which often rely on satellite communications. In these cases, edge analytics are unlikely to experience connectivity interruptions that would prevent continuous asset monitoring.
In one of the areas with the broadest relevance, applications involving the use of personal or sensitive data benefit from local processing and analytics because they mitigate exposure of the data and, therefore, limit the risk of a data breach.
Despite the inroads made by edge technology in the cloud’s role, cloud-based analytics are ideal for certain classes of applications, particularly in the industrial sector. “Transactional data for maintenance repair histories across fleets of equipment in multiple global sites is an example that could be solely cloud based,” says Kovanic. “An example of this can include the health of HVAC or refrigeration systems in a plant.”
That said, the sway of cloud analytics does appear to be decreasing. “There are no scenarios where the cloud should be the sole solution when it comes to IIoT,” says Ravichandar. “The amount of data collected and bandwidth required makes this cost-prohibitive.”
Designing for Edge Analytics
Even though edge analytics and the machines that support them are still in the early stages of their evolution, the experiences of early adopters have begun to provide a set of best practices to guide designers. These prove invaluable because developing edge analytics systems requires design teams to consider a broad spectrum of factors when creating new products. The situation is further compounded by the fact that each application has its own requirements. There is, however, one issue that is always relevant: the lifecycle of the product.
To address this issue, the designer has to decide at the outset whether the product has fixed functionality or is software defined and upgradeable. If the goal is a software-defined design, best practices require the design team to follow a set process.
“A software-defined approach requires sufficient compute, storage and connectivity resources for the entire lifecycle,” says Formisano. “Once the lifecycle is understood, the design engineer must decompose the IoT use case to its essential functions at the edge and map them to the constraints of operating at the edge. Some of the more important constraints include the cost, thermal condition, size, I/O, connectivity, power, data formats, protocols and security and privacy considerations.”
Addressing this overarching issue, however, is just the beginning. See the “Designing on the Edge” checklist to the left for more. All of these issues boil down to one rule of thumb: Keep the capabilities of the end point where the edge analytics will operate top of mind. Smaller devices require more planning.
“There are different kinds of end points: gateways with a lot of bandwidth and processing capabilities, and constrained end points that operate on battery with little processing capabilities and small bandwidth,” says Olivier Pauzet, vice president and general manager, IoT solutions business unit, Sierra Wireless. “For constraint end points, a lot of tight integration between the hardware, embedded software, network and cloud will be required to build an efficient system.”
Network Issues
This rule takes you to the next item on the designer’s checklist: the network’s architecture. “We should design an edge network that has the elasticity to grow and shrink as more processing power, memory and data storage are required,” says Formisano. “The nodes in the edge network should be allowed to be added or removed as required by the data and processing loads on the network to ensure successful accomplishment of the targeted throughput and latencies.”
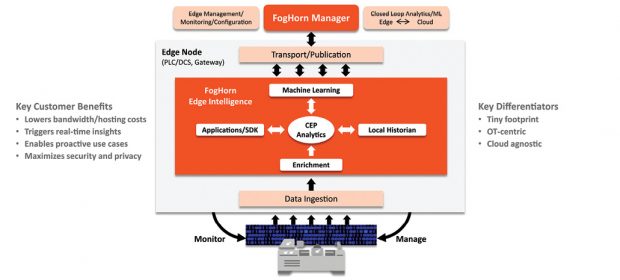 Edge analytics stores, processes and analyzes sensor data close to where it is generated. Technology providers have begun to offer scalable platforms that meet these requirements, sidestepping the cost of moving data to and from the cloud, the latency associated with moving data and the problems arising from intermittent connectivity. Image courtesy of FogHorn Systems.
Edge analytics stores, processes and analyzes sensor data close to where it is generated. Technology providers have begun to offer scalable platforms that meet these requirements, sidestepping the cost of moving data to and from the cloud, the latency associated with moving data and the problems arising from intermittent connectivity. Image courtesy of FogHorn Systems.On top of this, developers must enable edge networks to manage their own health. This means architectures should include mechanisms that autonomously perform load balancing, workload migration and workload redistribution among the nodes of the edge network.
In addition, the architecture should enable smooth optimal deployment based on heterogeneous node configurations. This means each node in the edge network can have its own configuration in terms of memory, processing power and data storage.
Moving Machine Learning to the Edge
Even as devices and gateways become more powerful, developers of edge analytics systems must still overcome two key hurdles before these machines can reap the full benefits of machine learning: device size and deployment experience.
Many smaller intelligence machines have limited-capacity memories and processors. The problem here is that state-of-the-art machine learning techniques are not a good fit for execution on small, resource-constrained devices. To adapt machine learning to these operating environments, data scientists must develop compressed machine learning algorithms tailored for platforms that often use the lowest cost processors. This means balancing accuracy with runtime resource consumption.
The second challenge revolves around the fact that information technology and operational technology staff have a wealth of process and equipment expertise, but often have limited experience with deploying machine learning systems. To address this hurdle, developers and data scientists must create tools and platforms that will enable these critical players to engage with and create their own machine learning algorithms without coding.
Although these are serious impediments to inclusion of machine learning in edge analytics, developers have begun to find ways around these barriers. For example, many companies have already started to embrace open-source machine-learning libraries to build better tools and enhance collaboration. In addition, machine-learning-as-a-service promises to mitigate adoption barriers.
Machine learning will certainly play a key role in edge analytics, new intelligent machines and the IoT. These areas are, however, still works in progress. What machine learning will look like in these applications when it finally grows into its role has yet to be determined.
More Info
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News


