GigabitE & InfiniBand Vie for Cluster Interconnect
The choice depends on the characteristics of the cluster applications to be run.


Latest News
October 1, 2008
By Michael A. Schulman & Josh Simons
 The Sun Blade X6220 Server Module is shown here containing two AMD Opteron processors. |
Applications such as those used for finite element analysis (FEA) and crash analysis have evolved over the past 15 years to take advantage of changing trends in parallel computing systems. The first wave of parallelization exploited the multiple CPUs and large memories available in single, symmetric multiprocessor (SMP) systems. Further development was then required to take advantage of cluster systems: cooperating groups of systems connected by high-speed interconnects.
The use of cluster systems has become a dominant trend in high-performance computing (HPC) over the past decade. Initially pursued as a less-expensive alternative to large SMP systems, clustering has become an essential mechanism for delivering scalable performance beyond what is available on single systems of any size.
HPC Interconnects
In a cluster environment, applications exist as sets of cooperating processes spread across the nodes of a cluster, with data transfers occurring between those processes as needed to perform required computations. To support this style of distributed application, new programming models have been developed. The primary model in use today is called message passing and the most widely available standard is MPI (message passing interface), which supports a variety of data transfer and other primitives that are well matched to the requirements of these parallel, distributed cluster applications. As one can imagine, the characteristics of the interconnect (e.g., bandwidth, latency, scalability) that is used to tie together the nodes in a cluster system can have a dramatic effect on the ultimate performance of this type of application.
The two most popular HPC interconnects in use today are Gigabit Ethernet (GbE) and InfiniBand (IB). GbE has the benefit of being both ubiquitous and inexpensive due to the fact that most systems shipped today have built-in GbE interconnect included on their mother- boards. InfiniBand, by contrast, while costing more and requiring the addition of a plug-in card in each cluster node, offers considerably higher bandwidths and much lower latencies. Current InfiniBand technology (referred to as 4x DDR — double data rate) offers 16Gbps of bandwidth (roughly 16x that available with GbE) and latencies on the order of 1-2 micro-seconds as compared to typical GbE latencies of about 30 microseconds (ms).
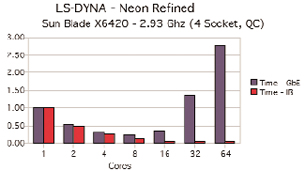 Figure 1: In LS-DYNA, the total elapsed times to run the application with a given input test case. |
What Will Run
The choice of appropriate cluster interconnect depends in large part on the characteristics of the cluster applications that will be run on the system. Depending on the algorithms used in their implementation, the performance of parallel distributed applications can vary widely depending on interconnect characteristics. For applications that primarily transfer large pieces of data between communicating processes, available interconnect bandwidth is the primary concern: the faster data can be moved, the faster the application will run. However, for applications that transfer many very small pieces of data between processes, latency becomes the critical factor: the inherent delay built into the transfer process itself (the overhead of moving data through the system and across the interconnect to a receiving system) can be a limiting factor, reducing overall application performance.
Let’s look at some applications that use intersystem communication to speed up the application. The TOP500 listing of the world’s fastest computers uses a rather simple benchmark to rank systems. The LINPACK benchmark computation, which solves a set of linear equations, can be spread across many processors and scales using thousands of cores. The June 2008 TOP500 list of the world’s fastest computers shows that GbE is used at 57 percent of the sites, while IB is used at about 24 percent of the sites. None of the other interconnect technologies garner more than about 3.5 percent of the total.
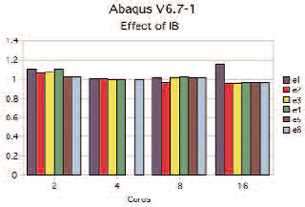 Figure 2: The Abaqus simulation shows performance differences related to the choice of GbE or IB. |
Number of Cores
Looking at a real-world, end-user application for crash analysis gives more insight into the actual importance of interconnect choice. The LS-DYNA application, from Livermore Software Technology Corp., mathematically simulates many non-linear behaviors in materials as forces act upon them. When running LS-DYNA on a cluster, we can look at how the application performs as we vary the number of processor cores, using either GbE or IB as the system interconnect. The results are summarized in Figure 1, as the application is run on a varying number of cores. We compare the total elapsed times to run the application with a given input test case.
In Figure 1, LS-DYNA was run on a small cluster, increasing the number of cores that were used for the application. The system consisted of 8 blades, each containing 2 sockets of a quad-core chip. A single core was used on each of the 8 blades, up to 8 cores, to compare the inter node communication that would be needed.
The input data set, Neon Refined, is a standard test case for LS-DYNA. It is a frontal crash with initial speed at 31.5 mph and a model size of 535K elements. The simulation length is 150ms. The model created by the National Crash Analysis Center at George Washington University is one of the few publicly available models for vehicle crash analysis based on a 1996 Plymouth Neon. (This model was run up to 64 cores, using both GbE and IB.) As can be seen in Figure 1, either interconnect performs when using a low number of cores. The application scales quite well from 1 to 8 cores, whether using GbE or IB. However, above 8 cores, starting with the tests at 16 cores, the time for the application to complete starts to grow, while the IB version continues to show performance improvement, although not as well.
When testing with 64 cores, the GbE version would be unusable, as the slowdown in overall performance has increased to very high levels. As an application like this scales to use more cores, the amount of actual work per core may decrease, as the model is broken up into smaller areas. Thus, more communication must take place between the cores and the application must communicate with more of its processes, running on the different systems. In this case, the slower network (GbE) gets saturated, and the CPUs must wait for results from other systems in order to continue their work. Thus, although much less expensive than an IB implementation, the GbE results at a core count above 8 simply does not make sense.
The Next Speed Bump
Certain applications, however, do not require the increase in speed of InfiniBand over GbE. Running Abaqus, for example, across a range of core counts using standard test cases shows only minor performance differences related to choice of GbE or IB.
As the number of CPU cores available in cluster nodes continues to grow as a result of the industry trend toward multicore and multithreaded processors, it will be important for the performance of cluster interconnects to keep pace with these changes to maintain a balance between computation and communication. Both Ethernet and InfiniBand are positioned to do exactly that. 10 GbE is now becoming broadly available, though at price points that are generally too high for use in HPC cluster systems. However, as prices continue to drop, 10 GbE will be well positioned to perform as an excellent cluster interconnect for those applications not requiring low latency capabilities. As for InfiniBand, the next speed bump (called QDR — quad data rate) will soon be available. Offering a bandwidth of 32Gbps and extremely low latencies, QDR IB will be positioned to maintain its position as a popular cluster interconnect, suitable for the most demanding of application requirements.
Evaluate Systems
Modern blade systems like the Sun Blade X6250 and the Sun Blade X6220 support up to 16 cores per node. With that many computing elements in a single enclosure it is important to determine how the nodes should be used in an MCAE environment. The overall performance of an application with a defined input set is dependent upon a number of factors. The CPU speed, amount of memory, type of I/O, and the interconnect will all contribute to the speed at which an application runs. It is important to benchmark and determine core and node loading conditions when evaluating the type and number of systems that are best for the desired application.
More Info:
Livermore Software Technology Corporation
Livermore,CA
lstc.com
Sun Microsystems
Santa Clara,CA
sun.com
TOP500
top500.org
Michael A. Schulman is a marketing manager in the HPC group at Sun Microsystems. Josh Simons is a distinguished engineer at Sun with 20 years of experience with HPC systems and software. Send comments about this article to [email protected].
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News
About the Author
DE’s editors contribute news and new product announcements to Digital Engineering.
Press releases may be sent to them via [email protected].


