Helping design and engineering professionals discover, evaluate and specify technologies and processes that shorten the design cycle and enable success.

Cut Retrieval-Augmented Generation (RAG) Hallucinations by 50%
Most teams hit the same wall with enterprise AI: LLMs that hallucinate, pipelines that don’t scale, and infrastructure that’s harder to design than the models themselves.

What Is Intelligent BOM Management? A Guide to Smarter Product Development
Learn how intelligent Bill of Materials (BOM) management helps teams collaborate, reduce errors, and bring innovative products to market faster with cloud-based PLM tools.
Some years ago, there was speculation that the high-performance computing (HPC) segment of the computer industry might not be able to ride the Moore’s Law acceleration curve for much longer. But when raw CPU processing speed began to slow down, the industry responded with more targeted and nuanced solutions to improve performance.
Intel delivered Xeon Phi, a next-generation CPU for HPC with considerable improvements in parallelism, vectorization and power efficiency. GPU capabilities from NVIDIA and AMD increased beyond expectation. HPC cluster connection standards such as Gigabit Ethernet and InfiniBand kept pace with improved performance and lower costs. Creative solutions such as “carpet clusters” became more common for getting the most computational bang for the buck.
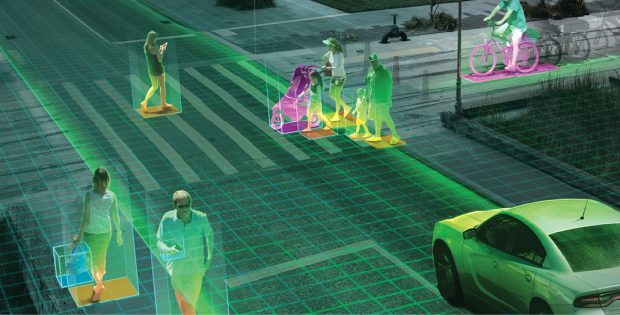
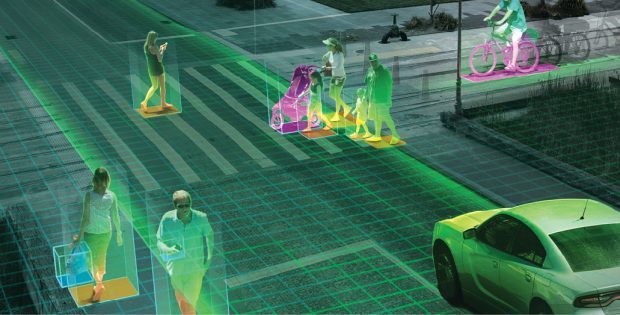 Autonomous driving and smart cities data integration will increase demand for dedicated engineering computing clusters. Image courtesy of NVIDIA.
Autonomous driving and smart cities data integration will increase demand for dedicated engineering computing clusters. Image courtesy of NVIDIA.The net result is that computer clusters for HPC continue to be a viable solution for engineering teams, along with workstations, virtualization, cloud computing and on-site data centers. Whereas a year or two ago there was talk that cloud computing might completely replace HPC clusters, today such clusters still play an important role.
There are basically three types of HPC clusters in use today for engineering and manufacturing.
1. The first is the standard HPC cluster of several off-the-shelf workstations or servers, which continues to be an industry mainstay. They increase computer performance exponentially over the use of a single workstation, and they continue to pass on significant cost savings over SMP (symmetric multiprocessing) and MPP (massively parallel processing) systems, based on the use of lower cost hardware made for the wider professional market.
2. The second common engineering cluster today is assembled from linked GPU or Xeon Phi computers. These systems have become possible because of the combination of more powerful hardware options and better software for using GPU and Xeon Phi technology in clusters.
3. A third form of cluster becoming more popular in engineering is the dedicated visualization cluster, as more users realize there is long-term benefit in reusing visualization data, and market expectation for real-time simulation rises.
 Several vendors including Advanced Clustering Technologies still see a strong market in workgroup and small department engineering clusters. Image courtesy of Advanced Clustering Technologies.
Several vendors including Advanced Clustering Technologies still see a strong market in workgroup and small department engineering clusters. Image courtesy of Advanced Clustering Technologies.“I’ve never seen a visualization department in a manufacturing firm bigger than 20 users,” says Chris Ruffo, the worldwide AEC and Manufacturing market manager for Lenovo. “They want small clusters within the company and they don’t need the corporate data center.”
HPC clusters are increasingly being viewed as a hub service, the central computing resource that centralizes the use of other computation sources such as commercial cloud or a separate in-house data center. The cluster is used for both collection and computation. (See also “The HPDA Buzz,” DE, June 2017: digitaleng.news/de/the-hpda-buzz.) The in-house HPC cluster is also becoming the first platform for experimental work in such fields as machine learning and artificial intelligence. Engineering firms want to explore these new features but are discovering the cloud is a very expensive place for prototyping and learning how to use new computational technologies.
“The in-house cluster becomes a sandbox for exploration, without the expense of Amazon Web Services or Microsoft Azure,” says Ruffo. Companies can then scale to the cloud or a larger in-house server installation as needed.
“It is all about managing costs,” adds Scott Ruppert, workstation portfolio manager at Lenovo. Carpet clusters—ad hoc HPC clusters created by linking department workstations—are for content creation, rendering simulation and machine learning. “A cluster in a back room may not be spun up all the time,” Ruppert notes, which means more expensive computing in the long run. Carpet clusters and workgroup HPC clusters can be assembled using less expensive hardware, and they can be more economically upgraded as technology improves. “The cloud is the safety net, not the primary resource,” he adds.
Computer vendor Fujitsu continues to see a good market for cluster computing. Because it is an integrated software and hardware vendor, Fujitsu can add software layers into the cluster to fine-tune a cluster for each customer. Their HPC Gateway defines a model for each application a company desires to use, which can then be used on both individual workstations and clusters. HPC Gateway can also automatically attach to predefine on-demand computing resources.
“Customer requirements are increasingly driven by data intensity as much as compute,” says Ian Godfrey, director, Solutions Business, Fujitsu Systems Europe. “These days HPC may be viewed within a larger operational context.” The size of the job changes much more often than the nature of the work to be done, making it easier for engineering groups to optimize clusters for a specific type of work, such as FEA.
Fujitsu says its internal market research shows that HPC-reliant economic sectors in the United States contribute around 55% of total gross domestic product. “We have seen the customer’s appetite for performance and throughput never diminishes,” adds Godfrey. “They are always finding new processes or models that consume newfound power and then they push further with their modeling, looking for ever finer resolution, simulating more scenarios and identifying new domains of digitalization and virtual prototyping.”
Like Lenovo, Fujitsu sees growth in the use of HPC for machine learning and related data intensive computing tasks not directly related to visualization. “Machine learning algorithms, accelerated with the latest generations of HPC technology, offer new potential for processing large data volumes more rapidly, be more adaptable to new forms of data and reveal previously hidden information,” notes Godfrey. Fujitsu predicts more engineering departments will explore the use of multiple small clusters, divided by task, whenever the cost/benefit gains of dedicated HPC hardware beat the use of larger but more distant options.
Fujitsu does not see much HPC/cluster market erosion due to cloud computing. “We can detect an increase in workload [on clusters] as more data-driven tasks and projects enter the engineering scope,” Godfrey says. Although some are investing in dedicated clusters, others are taking the hybrid approach to “build upon standard processes to explore new potentials” such as evaluating a multidisciplinary optimization problem.
Clusters remain a flexible and cost-effective way to deploy high-performance computing to small work groups, even as new solutions in corporate data centers and cloud computing come to market. Vendors are continuing to invest in cluster technology, even as they assemble new solutions designed specifically for software products like new ANSYS Discovery Live, which is designed for a single workstation equipped with NVIDIA GPUs.
Because GPU capability is increasing faster than CPUs, both hardware and engineering software vendors will continue to invest in HPC innovations that take advantage of the new massive parallelism coming to market. More software will offer multicore and multinode parallelism, as well as innovations in their use of neural network technology.
More than ever, it is data that will be the determinant of HPC deployment. The first generation of engineering clusters were driven by increased use of simulation applications. Now other departments are creating massive amounts of data, requiring specific solutions scattered throughout the manufacturing enterprise. New internet of things and digital twin applications will supply data in real time, driving new demand for predictive performance computing and requiring their own dedicated platforms.

Randall S. Newton is principal analyst at Consilia Vektor, covering engineering technology. He has been part of the computer graphics industry in a variety of roles since 1985.
Follow DEJoin over 90,000 engineering professionals who get fresh engineering news as soon as it is published.



About Us · Contact Us · Editorial Team · Advertising · Privacy Policy · Subscriber Services · © 2026 Digital Engineering 24/7 · Peerless Media