Helping design and engineering professionals discover, evaluate and specify technologies and processes that shorten the design cycle and enable success.
Alert!
Digital Engineering ceased publication on July 1, 2026. This website remains available as an archive of engineering content.
For inquiries or information, please email [email protected].

Cut Retrieval-Augmented Generation (RAG) Hallucinations by 50%
Most teams hit the same wall with enterprise AI: LLMs that hallucinate, pipelines that don’t scale, and infrastructure that’s harder to design than the models themselves.

What Is Intelligent BOM Management? A Guide to Smarter Product Development
Learn how intelligent Bill of Materials (BOM) management helps teams collaborate, reduce errors, and bring innovative products to market faster with cloud-based PLM tools.
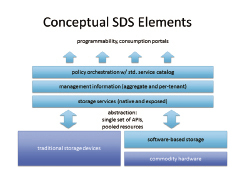 Software defined storage can be used to turn storage hardware into an easily accessible central repository. Courtesy of EMC. |
Storing engineering simulation data has become a significant challenge for businesses today. After all, most simulations are run numerous times, and the results -- as well as the source information -- can take up gigabytes, if not terabytes of valuable storage space.
What’s more, as processing power increases, multiple simulation runs are becoming commonplace. While this trend allows engineers to investigate many more what-if scenarios, it also creates even more data that must be easy to access, able to move quickly across the infrastructure and grow exponentially.
Complexities Abound
If you ask Graham Chapman, director of engineering for Morgan Motor Co., why simulation data is so important for the development of automobiles, he will come back with a long laundry list of the benefits of simulation, which can range from proving aerodynamics to crash engineering to the noise, vibration and harshness (NVH) simulations that can have an impact on design.
While Chapman would never discount the value of simulation, he can be heard decrying the technological challenges that simulation presents. “The amount of data stored and the number of sensor inputs are on the rise, as well as the number of simulation runs,” he adds. “The flexibility offered by today’s simulation applications means that more simulations can be performed and more scenarios investigated.”
Chapman points out that simulations can save countless hours of physical testing by eliminating many of the “what-if” scenarios found today with product design and development. But running complex simulations also uses resources at an exponential rate, meaning that more data has to be managed, tests orchestrated and more comparisons of results must be performed.
Chapman is far from alone in his observations. Keith Meintjes, Ph.D., practice manager, simulation and analysis for CIMdata, notes that “engineering simulation data is unique when it comes to product development, simply because context proves to be the key element for determining value of simulation data.”
According to Chapman, context should be defined as knowing what inputs produced the simulation result -- such as design maturity of the part or vehicle as well as other critical pieces of data. He observes that context goes beyond inputs, and should include knowing what simulation tools, simplifying assumptions, and versions of software were used.
Simulation results are usually temporary, but they still produce gigabytes of data. Engineers often want to continually analyze those large data sets and develop reports and recommendations, which in turn are offered as long-lived results, requiring archiving and management. This is unlike the raw results, which users are forced to delete because of the amount of space consumed. That often proves to be regrettable, simply because that raw data may have additional value and could be used for other projects -- or even reduce the need for additional simulations.
Adding to the storage conundrum is the fact that much of that raw data, and even completed reports, tend to be scattered throughout an organization. They reside in such disparate places as corporate databases, shared drives or even an engineer’s personal hard drive. That translates to data storage needs multiplying, especially in the case of duplicate information, where the same data may exist in many places, consuming valuable storage real estate.
What’s more, scattered storage makes it much harder to organize and share simulation data across multiple users or organizations. Even worse is the fact that the data may differ from one source to another, thanks to file revisions and updates that are not replicated everywhere. Add to that situation the complicated requirements of data backup and data protection, and a situation emerges were data can be easily lost to equipment failures, theft or malicious acts.
Scattered and unmanaged data proves to be a less-than-ideal way for organizations to protect their intellectual property, especially costly simulation run results.
Is More Technology the Answer?
Too often, enterprises simply throw technology at the storage problem. However, buying more storage hardware and the related subsystems is not always the correct answer to meet growing demand, especially when IT management cannot predict growth. The reality is that few enterprises have a solid handle on how storage resources are even being used throughout a large enterprise. Most ignore the efficiencies of centralized storage, instead focusing on the short-term benefits of siloed storage elements, which can be controlled independently of one another.
That said, technology still may prove to be the salve for growing storage needs for high-speed analytical data and raw data files that permeate engineering departments worldwide. But rather than taking the form of bigger and faster physical disks, the technology is comprised of better management of the storage systems that are already in place.
Virtualization technology has given birth to a new storage paradigm, where large storage arrays can be managed in a highly flexible fashion: software-defined storage (SDS). Simply put, SDS allows abstraction of storage services from the physical storage hardware, turning storage hardware into a virtual depot of data, which can be centrally managed and re-provisioned with ease.
Dozens, if not hundreds of vendors are playing in the SDS space, offering a wide variety of solutions that range from open standards-based solutions to proprietary products that only run on a particular vendor’s platform. Nevertheless, IT managers looking to transform storage from a static environment to a virtualized data warehouse need only look to the current market for readily available solutions from the likes of Dell, EMC, HP, IBM, NetApp and VMware.
Of course, the latest and greatest SDS solution means little if the data itself is not managed properly. SDS provides the closet space; engineers still have to figure out how to hang their coats. They can use the hangers provided by simulation data management (SDM).
Data Governance
According to GE Aviation’s Oscar Morataya, SDM offers one of the best paths to gain control over simulation data and promote its reuse. The concept also makes it easier to share simulation data for collaborative purposes, and brings a new methodology to dealing with the massive amounts of data generated by engineering simulations. In short, SDM allows engineers to govern and track the raw data, and keep it organized and available as needed.
Morataya explained the benefits of SDM during a presentation at Siemens PLM Software’s NX CAE Symposium, which took place last fall in Cincinnati. Morataya pointed out that capturing the context of simulation data brings long-term value to SDM by allowing that data to be reused, shared or otherwise manipulated for future use.
Although not a new idea, SDM is garnering interest among multiple businesses, especially those firms that are heavily vested in engineering and design services. Many vendors and project managers consider SDM as a functional subset of product lifecycle management (PLM), and that SDM should always be integrated into PLM.
Morataya summarized the value opportunities of SDM as security, quality, productivity, innovation, lowered costs and knowledge management -- backing those assumptions up with observational experience. For example, he explained that security is enhanced by the inclusion of export control policies, as well as the protection of intellectual property. Simply put, if the simulation data can be managed, then access and movement can be controlled.
Morataya also pointed out how SDM offers improved quality control, enabled by the abilities of SDM to orchestrate simulations while tracking the results. SDM gives users better control over configuration management, embraces design accuracy rules and offers a “first-time-right” paradigm.
SDM also helps to reduce operational costs two ways:
1. simplifying the control and orchestration of simulation data; and
2. reducing overall storage needs by eliminating duplication and discarding easily recreatable data elements.
Of course, SDM delivers on the promise of productivity enhancements. Morataya points out that SDM makes it simpler for global collaboration, while enforcing data management. This saves time and labor. Ultimately, it can be integrated into PLM, delivering a holistic approach to product management -- from prototype to delivery.
However, SDM may introduce additional challenges to organizations looking to maximize the value of simulation data. Morataya told attendees that adopting SDM requires revamping business processes and training users on the nuances of process management, all while calculating costs, implementing storage management and orchestrating the movement of legacy data into the system.
Another challenge can be related directly to the in-place file systems, such as NAS, SAN and storage arrays: the ability to move large amounts of data or files quickly and reliably. After all, if it takes longer to move the data than create it, cost reductions and productivity gains are negatively impacted.
The Choice is Yours
For those venturing into the realm of SDM, choices abound. Traditional vendors, such as Altair, ANSYS, Dassault Systemes, PTC, MSC Software and Siemens PLM Software offer a variety of solutions, ranging from cloud-based options to applications that integrate with design suites. It all comes down to choosing what works best for a given environment.
With SDM, the context of a past simulation can be used as the starting point in a new, similar prototype design. What’s more, SDM automation speeds processes up by automating data inputs. This allows additional simulation runs -- with more variations accomplished by automatically varying the inputs -- which allows engineers to quickly understand how a design will react to slight variations.
For most engineering operations, implementing SDM has become not a matter of if, but when.
Frank Ohlhorst is chief analyst and freelance writer at Ohlhorst.net. Send e-mail about this article to [email protected].
More Info

Frank Ohlhorst is chief analyst and freelance writer at Ohlhorst.net. Send e-mail about this article to [email protected].
Follow DE


About Us · Contact Us · Editorial Team · Advertising · Privacy Policy · Subscriber Services · © 2026 Digital Engineering 24/7 · Peerless Media